

In the last few years, image tagging problem has become an active research topic due to the urgent needs to categorize, retrieve and browse digital images via semantic keywords. However, manually labeling is labor costing, and tags crawled from the surrounding contexts of an image are usually problematic. To address these problem, we developed a set of automatic image tagging algorithms, based on Machine Learning techniques.
- Matrix Completion based Large-scale Image Tag Recovery 2013 - 2015
- Simultaneously enrich incomplete tags and remove noisy tags.
- Explore the tag interactions (both between tag keywords and tags of different images) via a low rank matrix completion component.
- Solve a convex optimization problem and thus computationally efficient. ( Most existing topic model solve a non-convex problem)
- Provide theoretical guarantees, i.e., statistical error bounds
- Capture the visual-tag dependency by a graph Laplacian
- Precision and efficiency are greatly improved compared with state-of-the-art tag completion algorithms.
- Adaptive to other image tagging tasks including image tag recommendation, tag ranking, and tag refinement.
- Could be easily extend to other information media like document, music and audio tagging/labeling tasks, and sentiment analysis tasks as well.
- Good scalability: adaptive to large datasets including NUS-WIDE(250K) and ImageNet 2014 (1.25M) in terms of both effectiveness and efficiency. (Codes for large scale data will come soon! :)
- Efficient Kernel Metric Learning for Large Scale Image Annotation 2012 - 2013
- Do not suffer from information loss by directly utilizing image annotations (effectiveness).
- Alleviate the overfitting risk via a Low rank regularizer (effectiveness, efficiency).
- PSD property is automatically ensured by regression (efficiency).
- Kernel matrix is approximated by Nystrom method rather than fully computed (efficiency).
- Precision was improved by 5% compared with state-of-the-art metric learning algorithms (LMNN, ITML, etc.).
Generally, user-provided tags with images in social media are incomplete and noisy, so we propose an efficient semi-supervised algorithm to solve the problem of tag completion that is able to simultaneously fill out the missing tags and remove noisy tags, where the tag correlations are fully explored through a matrix completion component.
Following the topic model, the tags of each image are drawn independently from a small mixture of multinomial distributions, which can be interpreted as a low rank enforcement and could be achieved through a nuclear norm minimizer. We show theoretically with recovery error bounds that the proposed noisy tag matrix recovery algorithm is able to simultaneously recover the missing tags and de-emphasize the noisy tags even with a limited number of observations. In addition, a graph Laplacian based component is introduced to combine the noisy matrix recovery component with visual features. The scheme of the proposed algorithm is shown by clicking here.
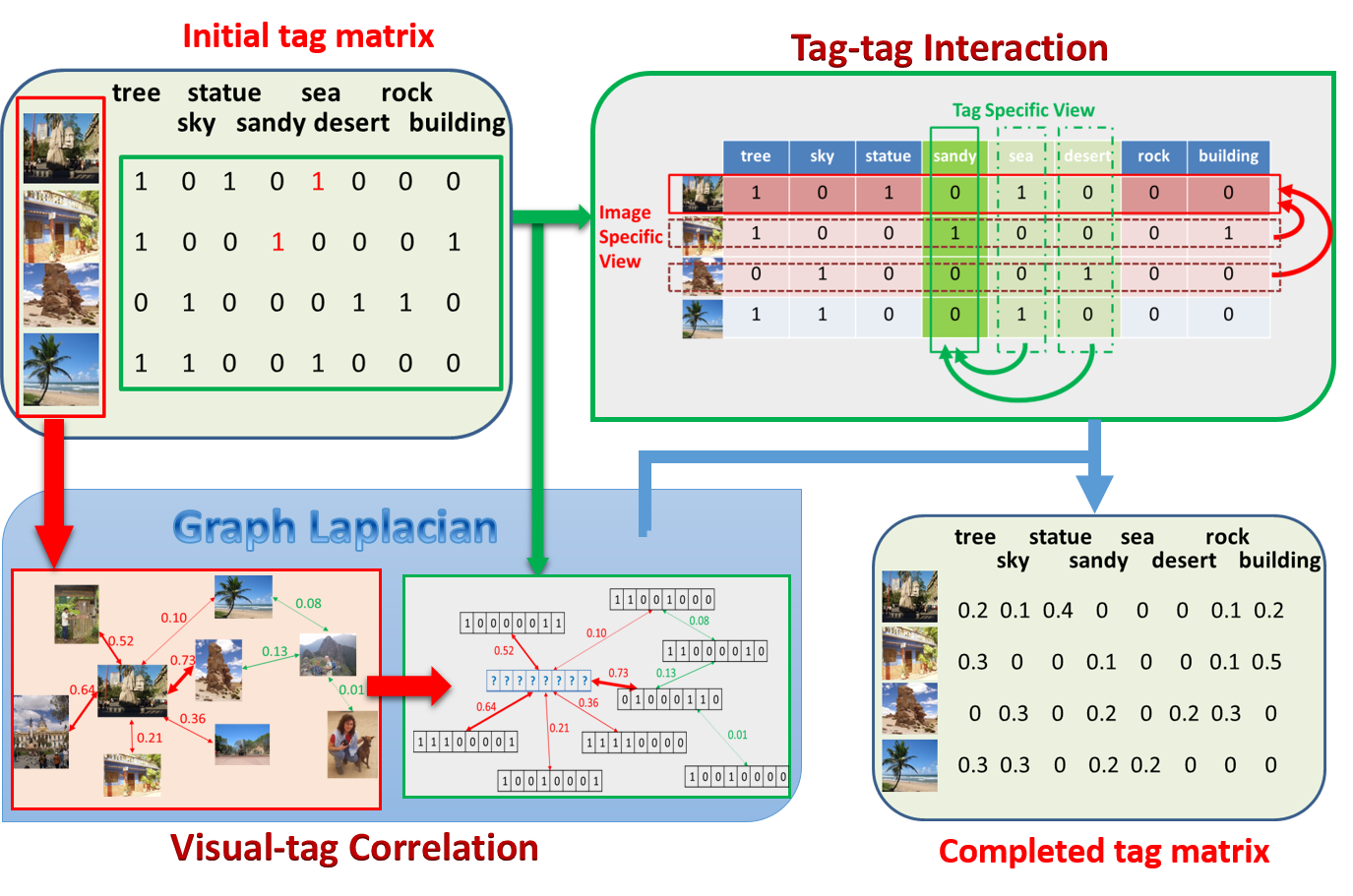{kind=link}
Songhe Feng, Zheyun Feng, and Rong Jin. "Learning to Rank Image Tags with Limited Training Examples". In IEEE Transactions on Image Processing (TIP), Vol. 24, NO. 4, April 2015.
Zheyun Feng, Songhe Feng, Rong Jin, and Anil K. Jain. "Image Tag Completion by Noisy Matrix Recovery". In European Conference of Computer Vision (ECCV), pp. 424-438, 2014.
One of the key challenges in search-based image annotation models is to define an appropriate similarity measure between images. Many kernel distance metric learning algorithms have been developed in order to capture the nonlinear relationships between visual features and semantics of the images. One fundamental limitation in applying kernel metric learning to image annotation problem is that it requires converting image annotations into binary constraints, leading to a significant information loss. In addition, most kernel metric learning algorithms suffer from high computational cost due to the requirement that the learned matrix has to be positive semi-definitive (PSD).
We propose a robust kernel metric learning (RKML) algorithm based on the regression technique. We provide the theoretical guarantee, i.e., statistical error bounds, and verify its efficiency and effectiveness for image annotation on flickr 1M dataset by comparing it to both state-of-the-art distance metric learning and image annotation approaches. The framework of RKML can be referred by click here.
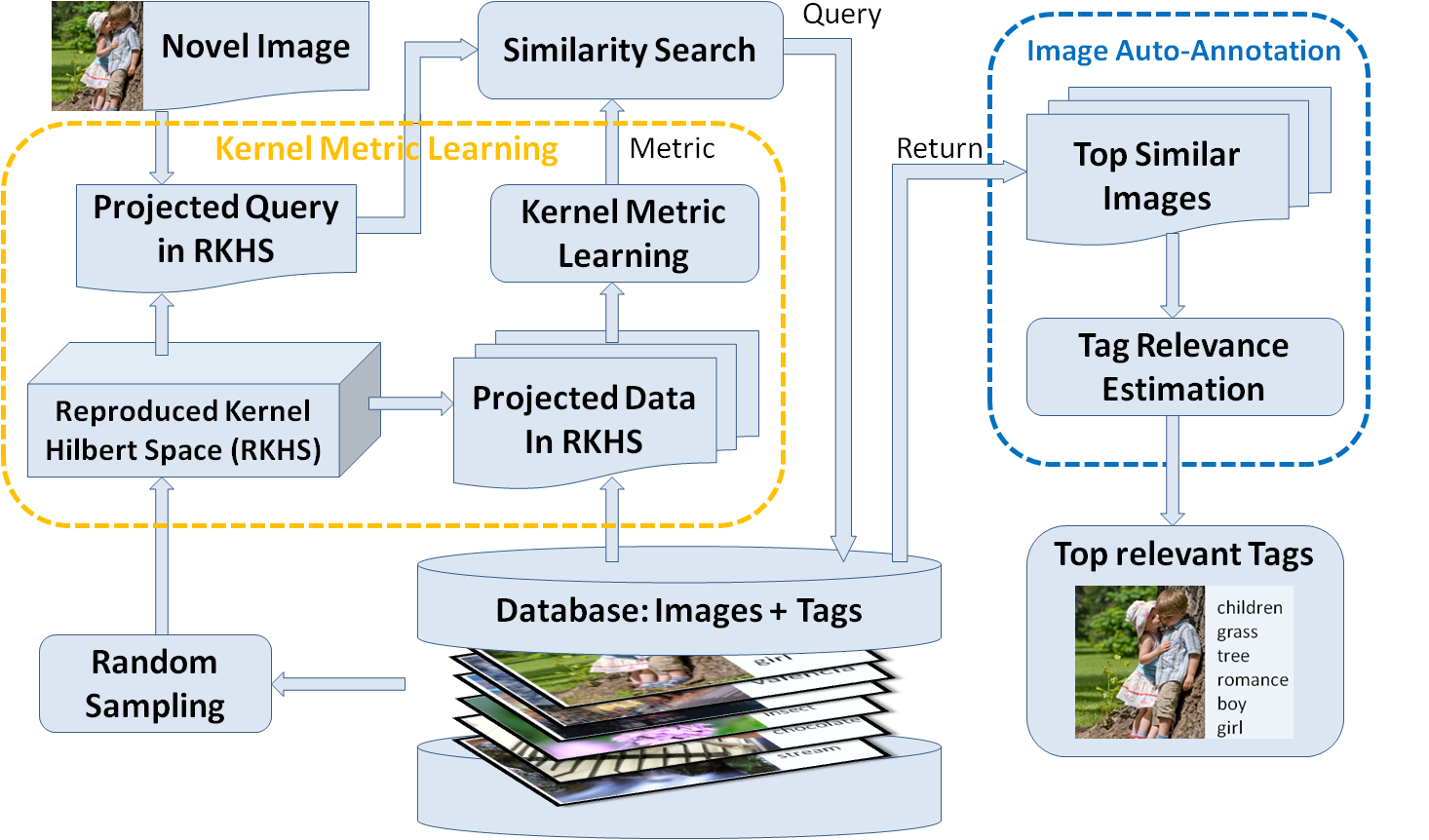{kind=link}
Zheyun Feng, Rong Jin, and Anil K. Jain. "Large-scale Image Annotation by Efficient and Robust Kernel Metric Learning". In International Conference of Computer Vision (ICCV), pp. 1609-1616, 2013.
Video processing is similar as image processing except that (i) the image quality is much worse, (ii) consecutive frames have similar images, (iii) requires to process and synchronize other media contents including audio and subtitle(document).
- Commercial (Advertisement) Detection in TV Programs 05/2013 - 08/2013 & 05/2014 - 08/2014
- Decoded videos and synchronized audio, image and subtitle streams.
- Designed a bottom-to-top commercial detection scheme, including frame, shot, and block layer feature extraction and analysis.
- Extract video features, including image feature and audio feature (MFCC, HZCRR, LSTER, SF) extraction, shot/block/program detection.
- Performed logo (both solid and transparent) detection/tracking, text detection and recognition, score/timer ticker detection and tracking.
- Extracted supervised information and train classifiers to detect commercial blocks for each video, using machine learning skills including decision tree, Naive bayesian, regression, sequential correction, etc.
- Achieve detection precision 98.6%, recall 98.4% to 102 Movies/TV show programs 2966 video blocks.
- Automatic Face Recognition and Content Analysis 07/2010 - 01/2011
- Shot detection based on Otsu threshold
- Detected faces using Viola-Jones methods and tracked them within a shot, i.e., connecting the same faces into a path using methods including optical flow, template matching and camshaft.
- Recognized the faces in the same path based on the Elastic Bunch Graph Matching algorithm. The training database was generated from the published photos of the cast.
- Chaotic Secure Communication System based on Public Wireless Network 04/2008 - 09/2008
- Compressed the audio/speech using G.723 protocol and encrypted it using Chaotic Pseudo-random Series (CPRS) algorithms.
- Stored additional information in silent frames of the compressed stream, and attached water mark and authority certification in the low bytes of encrypted data.
- Managed the communication between different terminals/processors, and enhanced the efficiency of the speech analysis, compression and encryption on DSP platform.
This project was done during my internship in Comcast Labs, DC in summers of both 2013 and 2014. It was part of the video content analysis project and it will turn out to be Comcast product soon! Presentation, Detailed feature extraction
This application was designed for two purposes: (1) Replace and distribute commercials in TV programs according to location and time, especially for programs produced by other companies (cbs, abc, fox, etc.), (2) Skip commercials when recording online TV show/program.
This project produced a metadata to describe the contents of a movie, including the scene, personage and corresponding descriptions, which facilitated the navigation within the video, and as well as the indexing/retrieval of movies via semantic keywords.
Document and Image Retrieval
- Document Retrieval and Query Expansion 05/2012 - 08/2012
- Studied and analyzed multiple scoring ways, and an Okapi BM25 based scoring way was proved to be the optimal to estimate the relevance score.
- Query expansion techniques, including pseudo relevance feedback, expansion using Google returned documents, synonym library (WordNet), latent semantic indexing and random walk methods, were applied to improve the retrieval performance. The expansion was based on the document analysis results, and was restricted in a certain domain (e.x., law cases).
- Basic text processing skills including tokenizing, stop words removal and stemming were used.
- Large-scale Efficient Range Search in High Dimensional Space 12/2011 - 03/2012
- Proposed a ransom projection based approach that converted a high dimensional range search to a sequence of one dimensional search.
- Random projected the data into a lower dimensional space, which was represented by vectors randomly sampled from a Gaussian distribution. Performed range search over the newly projected space.
- Conventional approach such as bysection, and KD-tree were used to speed up the search. Rademacher Represented projection space and the integration of fractal structure dramatically improved the efficiency.
- State-of-the-art hashing methods were compared and analyzed.
- Efficient Vector Representation for Kernel Similarity 09/2011 - 12/2011
- Derived a vector representation for image, which approximated the kernel similarity and promoted the computation. The vector was generated by a RBF kernel, which projected the images via a sequence of vectors randomly sampled from a normal distribution.
- The random sampled vectors played a similar role as clustering center, and the representation vector could be viewed as a histogram depending on the distance between visual words and key-points. Replacing clustering by simple random sampling dramatically improved the computation efficiency.
- Similarity between images could be expressed as an expectation over a dot product of the image vectors. Mahalanobis distance was used to reduce dimensionality.
Developed a large scale document retrieval application, which improved the retrieval performance by introducing different scoring ways and query expansion. Read More, Codes
This work was proposed for retrieval in large scale datasets and for large scale queries.
Data Classification and Clustering
- Business Risk Analysis 07/2015
- Preprocessed and analyzed the data, including converting different types of data to numeric, mutating the missing elements, dealing with conflicting data, scaling/normalizing the data, etc.
- Applied a ensemble of classifiers to achieve a good prediction performance.
- High Dimensional Classification with Fast Stochastic Gradient Descent Method 02/2015 - present
- Use a stochastic gradient descent method to solve a strongly convex optimization problem in data classification tasks.
- Achieve an optimal convergence rate O(1/T)
- ImageNet Classification with Multiple Classifiers 02/2013 - 04/2013
- Proposed an ensemble classifier to classify over 20K images sampled from ImageNet, with accuracy achieving 91%
- Multiple features including SIFT, GIST, LBP and HOG were used to better represent the image contents.
- Results of multiple classifiers (Kernel regression and kernel SVM) were merged in a weighting manner.
- Data Clustering using Genetic Algorithms 10/2012 - 12/2012
- Proposed a genetic algorithm worked well on problem of clustering large-scale high dimensional data even when the number of cluster is large.
- Two crossing set selection methods, six crossover approaches and a fine-tuning technique were used.
- Computationally efficient and achieved comparable performance as the most commonly state-of-the-art works on large datasets.
This was a data analysis project to help reduce financial business risk, where I made many efforts to analyze the customer data, deal with problematic (missing/conflicting) data, design the algorithm and evaluate it. Read More, Codes & Data
This is an undertaking project.
This was the course project of Pattern Recognition, where I applied the RKML algorithm (proposed in my ICCV13 paper) to multi-label classification problem and demonstrated its effectiveness and efficiency. Read More
This was the course project of Evolutionary Computation, where I made many efforts to design the algorithm, analyze and evaluate it. Read More
Image Processing and Analysis
- Analysis of Cardiac MRI with Tagging Lines 02/2011 - 05/2011
- Segmented and extracted the tagging lines on the magnetic resonance images. Different extraction methods were used, and the corresponding influences to the final 3D model were analyzed.
- Extracted heart information using techniques like tag removal and heart contour detection.
- Tagging sheets (Transverse, Sagittal and Coronal) were reconstructed from the clean tagging lines, and their deformation was tracked. Then a 3D cardiac deformation model was created based on the tagging information.
- Biopsy Image Analysis 04/2010 - 06/2010
- Accomplished segmentation and regularization of cytological images and histological images, and extracted the typical cellular or tissue components in order to detect the cancer cellular or abnormal tissue.
- Optimized the algorithm and improved the processing efficiency by adopting graph based tools including Grid, Region Adjacency Graph, Fully Connected Graph and Minimum Spanning Trees.
- Improved the segmentation accuracy using methods such as K-means based on color, texture segmentation based on entropy. Both unsupervised and semi-supervised methods were employed.
- Color Transfer between Images 02/2010 - 04/2010
- De-correlated the color space and adopting the color information from a photograph to a rendered image.
- Corrected the color globally or to certain clusters, using statistics methods, gamma correction and space shift.
- Studied and analyzed the transferring results in different color spaces, such as RGB, lab and CIECAM97s.
- Fingerprint Recognition System 03/2008 - 06/2008
- Background deletion, special block direction, enhancement of binary incorporation, skeleton thinning.
- Extracted minutiae (e.x., end minutiae and bifurcation minutiae) from thinned fingerprint images to match fingerprint. Eliminated false minutiae by edge-deleting and distance-threshold method.